Codeforces ran two contests this week. Hello 2020, as the name suggests, was the first round of the year (
problems,
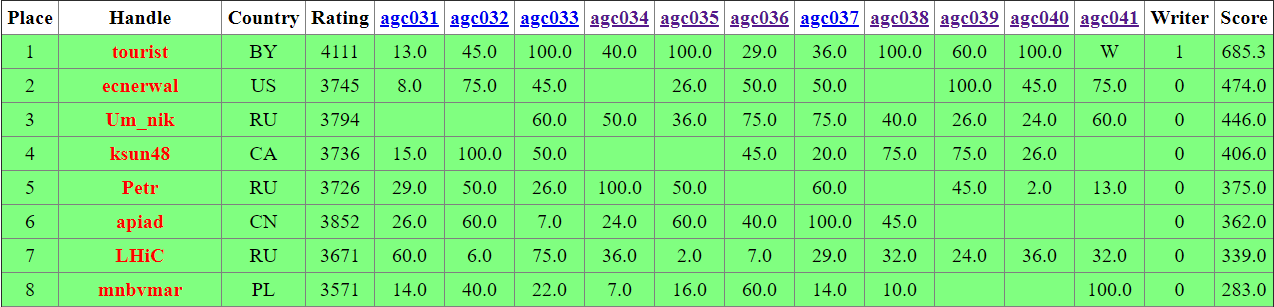
results, top 5 on the left,
my screencast,
analysis). Only four contestants could solve the hardest problem G, and only two of them also solved the remaining problems: mnbvmar and TLE. They had roughly the same speed as well, but mnbvmar only had two attempts that failed pretests compared to TLE's ten, and that's what made the difference. Congratulations to both!
I could solve the first five problems reasonably quickly, and I was quite excited about inventing the randomized solution to problem D and quickly recognizing that problem E is more or less equivalent to a very old problem about counting the number of 4-tuples of points that form a convex quadrilateral (I have a feeling that I wrote about it in this blog, but I seem to be unable to find the entry). However, the last two problems proved insurmountable for me, and I spent most of the time trying to get solutions that were clearly not the intended ones to work: max-flow on a graph of size n*log(n) in F (it turns out it was possible to succeed in this way — check out
izban's solution as an example), and repeated randomized search in G. I guess the time might have been better spent just thinking on paper, but then the screencast would not be so exciting :)
On a related note, quite a few people have noticed that I've switched to C++ in the recent contests, and asked why. I don't have much to add to
this Egor's comment. In the past I have tried switching to C++ a few times and noticed that I keep fighting with it during the contests instead of solving problems, and I do have a similar feeling now as well despite the better tools. However, I will try to keep using C++ for a longer time to see if things improve :)
Here is
the hardest problem from this round for you to try as well: you are given a 20x20 grid colored as a chessboard, with the top-left corner colored black. Some of the cells are removed from the grid, the remaining cells form a 4-connected piece and include the top-left corner. You need to insert some walls between the remaining cells in such a way that we get a
good labyrinth: there must be exactly one way to get from each cell to each other cell. Moreover, we want each black cell (remember the chessboard coloring) except the top-left cell to not be a dead-end in the labyrinth: each such cell must have at least two accessible neighbors.
Codeforces Round 612 followed a day later (
problems,
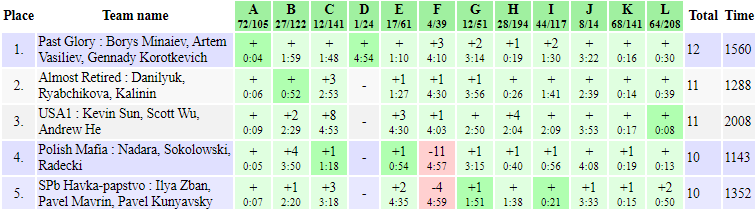
results, top 5 on the left). The sets of problems solved by the top contestants were very diverse (even though not visible in the top 5 screenshot, problem F was also solved by two contestants), but in the end ainta just solved more problems and won. Well done!
In
my previous summary, I have mentioned a couple of problems.
The first one came from AtCoder: an assignment of integer scores between 1 and
n (not necessarily distinct) to
n programming contest problems (
n<=5000) is called
good if for each
k the total score of every set of
k problems is strictly less than the total score of every set of
k+1 problems. How many good assignments of scores exist, modulo the given prime
m?
The first step to solve this problem is to notice that we can get rid of "for each
k" qualifier, replacing it with just
k=(
n-1)/2, rounded down. The reason for this is that in case the constraint is violated for smaller
k, we can just add the same problems to both sides to reach
k=(
n-1)/2, and in case it is violated for larger
k, the two sets necessarily have an intersection, so we can remove the intersection until we reach
k=(
n-1)/2 as well. Also, instead of "every set" we can say: the total score of
k problems with the largest scores must be less than the total score of
k+1 problems with the lowest scores.
To enforce that last constraint, it would be useful if our problem scores were sorted. This can be achieved with the following more or less standard process: we start with all problem scores equal to 1. Now we do the following
n-1 times: add 1 to a suffix of problem scores (this suffix could also be empty or all problems).
Now we can keep track how each such operation affects the value we're interested in: the sum of (
n-1)/2+1 smallest elements minus the sum of (
n-1)/2 largest elements. Going from the empty suffix to the full suffix, they change that value by 0,-1,-2,...,-(
n-1)/2,-(
n-1)/2 (if
n is even),-((
n-1)/2-1),...,-2,-1,0,1. Let's denote that multiset of changes as
C. In the end we need the value to be positive, and it starts with 1 (when all problem scores are 1).
Our problem can then be restated as follows: consider all ways to choose
n-1 values with replacement from the multiset
C (the same value can be chosen as many times as we want). How many ways have a non-negative sum?
Since the sum needs to be non-negative and the only possible positive change is 1, this yields a O(
n3) dynamic programming solution that can be sped up to O(
n2*log
n) and get accepted by skipping the states from which we can't reach the final state: let's process the elements of
C in decreasing order, and maintain dp
i,j,k as the number of ways to choose
j values from the first
i elements of
C such that their sum is
k. The answer is the sum of dp
n+1,n-1,k over all
k>=0.
However, there exists a magical way to speed this up to O(
n2). Let's rearrange our dynamic programming slightly: now we will process the elements of C in increasing order, and dp
i,j,k will now be the number of ways to choose
j values from the first
i elements of
C such that their sum is -
k. Also, we will stop before we process the only positive element 1 (because that would need special handling anyway as the sums stop being only negative), but also (!) before we process one of the two zeros that we have — in other words, we will only consider the first
n-1 elements of C in increasing order.
How to compute the answer from the last row of this dynamic programming? Suppose we have computed dp
n-1,j,k. Now we need to add some number of 0s and some number of 1s, let's denote those as
z and
o respectively. We need to have
j+
z+
o=
n-1 to get
n-1 total changes, and
k<=
o to get a non-negative sum. The solutions to these two constraints look like:
o=
k,
z=
n-1-
j-
k;
o=
k+1,
z=
n-1-
j-
k-1, and so on until
z reaches 0. The number of solutions is thus max(0,
n-
j-
k), so our answer is a sum of max(0,
n-
j-
k)*dp
n-1,j,k.
Here comes the magic: since max(0,
n-
j-
k) only depends on
j+
k and not on
j and
k separately, and since our transitions just add one to
j and the current element of
C to
k, and so the thing being added does not depend on the values of
j and
k themselves, we can collapse our dynamic programming states to keep track of
j+
k only, instead of
j and
k separately! This means we'll have O(
n2) states and O(
n2) complexity.
What remains a mystery is: how does one come up with this magic? I guess one could just stumble upon it while trying different approaches. Maybe a more principled way is to use the approach from
my old post: if we just implement the O(
n3) dynamic programming which processes the elements of
C in increasing order, and find out the contribution of each state to the final answer, we can notice that the contributions of states with the same value of
j+
k are the same and collapse them. Is there any other way that makes this observation look less magical?
The second problem I mentioned was from Codeforces: you are given
n integers
ai such that
i-
n<=
ai<=
i-1 (
i goes from 1 to
n), in other words one integer from [-(
n-1),0], one from [-(
n-2),1], ..., one from [0,
n-1]. You need to find any nonempty subset with a zero sum. You are guaranteed that such subset always exists, which is by itself quite a hint.
n is up to a million.
The key idea here is to realize that keeping integers from different segments is a bit clumsy, so let's shift the segments: the first one by
n-1, the second one by
n-2, and so on. Now all integers are chosen from the segment [0,
n-1] which is nice and symmetric, but instead of a zero-sum subset we need to find a subset where the sum of values equals to the sum of shifts.
To restate, we have reduced our problem to the following: you are given n integers
a0,
a1, ..., a
n-1, each between 0 and
n-1. You need to find a set
S of indices such that Σ
i∈Si=Σ
i∈Sa
i.
When I obtained this reduced problem during the round, it felt really familiar to me, so I've tried to google the answer without much success. It turns out that it's simply quite easy: build a graph from the arrows
i->a
i, and just find any cycle in this graph. The indices corresponding to this cycle will satisfy the equality above since the sums will just be the same numbers but in different order.
I will be doing a poll for the best problem of 2019 soon, and I will mostly be picking the candidates from the problems I explained in this blog. However, I realize that there were many great problems in 2019 that I just did not encounter, so if there is a problem you feel should be included in the shortlist that was in a contest that I did not participate in, please mention it in comments! Feel free to also post links to similar discussions, such as
this post.
Thanks for reading, and see you next week!