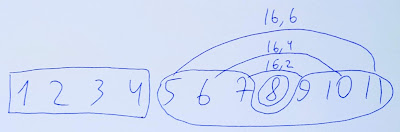Codeforces Round 768 on Thursday was the first event of last week (
problems,
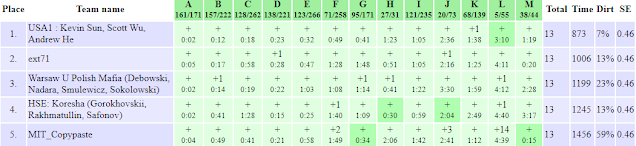
results, top 5 on the left,
analysis).
Um_nik has solved the hardest problem F
so much faster than everybody else that his gap at the top of the scoreboard is enormous, almost as if he has solved a seventh problem :) Very impressive!
CodeChef January Lunchtime 2022 followed on Saturday (
problems,
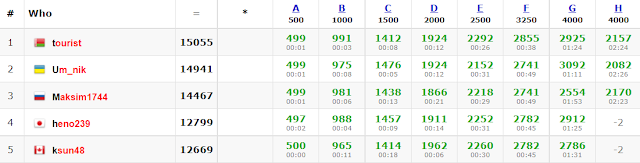
results, top 5 on the left,
my screencast,
analysis). I haven't solved IOI-format contests for quite some time, but I have dived right in, taking advantage of the fact that there is no penalty for incorrect submissions and wasting way too much time waiting for submission results :) For this reason, or maybe because I just had too many small bugs to find and fix,
gennady.korotkevich and
maroonrk were out of reach, getting to 500 points much faster. Well done!
In my previous summary, I have mentioned
a Codeforces problem: you are given a tree with vertices numbered from 1 to
n, initially all colored white. The tree edges have weights. You need to process a sequence of queries of three types:
- Given l and r, color all vertices with numbers between l and r black.
- Given l and r, color all vertices with numbers between l and r white.
- Given x, find the largest edge weight in the union of the shortest paths from x to all black vertices.
Both the number of vertices and the number of queries are up to 300000.
The first step in solving this problem is relatively standard: let's learn to effectively find the largest edge weight on a path in a tree. We will build an auxiliary new tree where the inner nodes correspond to the edges of our tree, and the leaves correspond to the vertices of our tree. We start by having just n independent leaves. Then we iterate over all tree edges in increasing order of weight, and for each edge we find the new trees containing its ends, then make a new tree vertex corresponding to this edge and make the two trees we found its children. This can be accomplished using a disjoint set union data structure.
You can see an example of an initial tree and a new tree corresponding to it on the right. Now, it turns out that the edge with the largest weight between any pair of vertices in the initial tree corresponds to the least common ancestor of those vertices in the new tree.
So in the new tree, the query of type 3 can be seen as finding the shallowest least common ancestor between the given vertex x and the black vertices, and it's not hard to notice that if we write down the vertices of the new tree in dfs in-order (in a similar fashion to how LCA is reduced to RMQ), then we just need to find the first and last vertices from the set {x, black vertices} in this order, and take their LCA.
Now we are ready to turn our attention to the queries of type 1 and 2. Consider the array where the i-th element contains the in-order traversal times of the i-th vertex of the original tree in the new tree. Then in order to answer queries of type 3, we need to be able to find the minimum and maximum value in this array over all black vertices. So, we need a data structure that supports the following operations:
- Given l and r, color all vertices with numbers between l and r black.
- Given l and r, color all vertices with numbers between l and r white.
- Find the minimum and maximum value of ai among all i that are colored black.
Given the range update and range query nature of this subproblem, it is reasonable to use a segment tree with lazy propagation to solve it. Indeed, the AtCoder library
provides a general implementation of such data structure that allows one to plug an arbitrary operation inside it. You can check out the
documentation for the details of how to customize it, but in short we need to come up with a monoid and a set of mappings (in effect, another monoid) acting on the elements of the first monoid in such a way that the distributive law applies, the range update is applying a mapping to all elements from a range, and the range query is multiplying all elements in a range in the first monoid.
This all sounds abstract, fine and dandy, but how to put our real problem into these algebraic terms? First of all, let's come up with the second monoid, the one that corresponds to the range updates (queries of type 1 and 2). This monoid will have just three elements: neutral, white and black, and the multiplication in this monoid will simply be "if the left argument is not neutral, then take it, otherwise take the right argument", which makes sense since the last color applied to a vertex overrides all previous ones.
Now, what should the first monoid be, the one that corresponds to the range queries? Since we need to find the minimum and maximum value of all elements that are colored black, it's logical to first try to have an element of the monoid store those minimum and maximum, with the natural operation that takes the minimum of the minimums and the maximum of the maximums.
However, it turns out that we can't make the whole system work: how would a "black" range update act on such a pair? It turns out we're missing information: the new maximum of all black elements should be equal to the maximum of all elements, because all of them are colored black after the range update, and we don't store and propagate this information yet.
So here's our second attempt at the range query monoid: its element stores four numbers: the minimum and maximum values of black elements in the corresponding segment, and the minimum and maximum values of all elements in the corresponding segment. The operation is also defined naturally, and we now have enough to define how "black" and "white" range updates act on it.
To summarize, both monoids that we use in our lazy segment tree are not very common:
- One where elements are quadruples of numbers, with the operation taking minimum of two numbers and maximum of the two others.
- The other with just three elements and a weird multiplication table.
I realize that this explanation is very abstract and can be hard to follow. Here's an excerpt from
my submission that defines the lazy segtree, maybe it will help:
- struct State {
- int minOn = INF;
- int maxOn = -INF;
- int minAll = INF;
- int maxAll = -INF;
- };
-
- State unitState() {
- return {};
- }
-
- State combine(State x, State y) {
- State r;
- r.minOn = min(x.minOn, y.minOn);
- r.maxOn = max(x.maxOn, y.maxOn);
- r.minAll = min(x.minAll, y.minAll);
- r.maxAll = max(x.maxAll, y.maxAll);
- return r;
- }
-
- State apply(int x, State s) {
- if (x == 0) return s;
- if (x == 1) {
- s.minOn = s.minAll;
- s.maxOn = s.maxAll;
- return s;
- }
- assert(x == -1);
- s.minOn = INF;
- s.maxOn = -INF;
- return s;
- }
-
- int combine2(int x, int y) {
- if (x != 0) return x; else return y;
- }
-
- int identity() {
- return 0;
- }
...
atcoder::lazy_segtree<State, combine, unitState, int, apply, combine2, identity> lazytree;
I was pretty happy with myself when I figured this out, even though that maybe just implementing a lazy segtree without explicit mathematical abstractions might've been faster :)
Finally, it turns out that last week the submissions (
1,
2,
3) generated by
AlphaCode were submitted to Codeforces. I got to take a look at them a couple of days before the publication, but I was not involved in any other way, so I was just as impressed as many of you. Of course, I think this is just the first step and we're still very far from actually
solving problems with ML models.
I found this submission to be the most helpful to understand the current state of affairs: the part before "string s;" is quite meaningful, and the model had to have a decent understanding of the problem statement to generate that loop. However, I cannot see any logical justification of the loop after "string s;", which seems to be a pretty arbitrary loop :) The reason the whole solution still works is that after the first part, in case the length of the result string is n-1 we need to append any of the two characters a, b to it, and an arbitrary loop can generate an arbitrary character.
This solution seems to suggest that the model can translate instructions from the problem statement into code implementing them, and also sometimes make small logical steps by the virtue of statement-guided random exploration. While this seems enough to solve easy Div 2/3 problems, I think the model needs to improve a lot to generate a solution of the type that I'd appreciate enough to mention in this blog :)
Nevertheless, this has still advanced the state of the art by leaps and bounds, so congratulations to the AlphaCode team!
Thanks for reading, and check back for this week's summary.